이전의 'DFS/BFS'와 '최단 경로'에서 다룬 것들 모두 그래프 알고리즘의 한 유형이다.
이외에도 그래프 알고리즘은 다양하고, 출제 비중이 낮더라도 제대로 알고 있어야 하는 알고리즘들이 존재한다.
앞서 다뤘던 그래프 알고리즘을 복습하자면,
그래프란 노드(node)와 노드(node) 사이에 연결된 간선(edge)의 정보를 갖는 자료구조를 의미한다.
문제를 접했을 때, '서로 다른 개체(혹은 객체)가 연결되어 있다.' 라는 언급이 있다면, 그래프 알고리즘 문제라고 의식해야 한다.
더불어 그래프 자료구조 중에서 트리 자료구조는 다양한 알고리즘에서 사용되기 때문에 꼭 기억해야하는 개념이다.
| 그래프 | 트리 | |
| 방향성 | 방향 그래프 혹은 무방향 그래프 | 방향 그래프 |
| 순환성 | 순환 및 비순환 | 비순환 |
| 루트 노드 존재 여부 | 루트 노드 없음 | 루트 노드 있음 |
| 노드간 관계성 | 부모와 자식 관계 없음 | 부모와 자식 관계 |
| 모델의 종류 | 네트워크 모델 | 계층 모델 |
또한 그래프의 구현 방법은 2가지 방식이 존재한다.
- 인접 행렬(Adjacency Matrix) : 2차원 배열을 사용하는 방식
- 인접 리스트(Adjacency List) : 리스트를 사용하는 방식
2가지 모두 그래프 알고리즘에서 많이 사용되고, 메모리와 속도 측면에서 구별된다.
노드의 개수가 V, 간선의 개수가 E인 그래프를 생각해보면,
인접 행렬은 간선 정보를 저장하기 위해 O(V^2)만큼 메모리 공간이 필요하지만, 인접 리스트는 O(E)만큼의 메모리 공간이 필요하다.
또한 인접 행렬은 특정노드(A)에서 특정 노드(B)로 이어진 간선 비용을 O(1)의 시간으로 즉시 알 수 있지만,
인접 리스트는 O(V)의 시간이 소요된다.
| 인접 행렬 | 인접 리스트 | |
| 메모리 공간 (공간 복잡도) | O(V^2) | O(V) |
| 속도 (시간 복잡도) | O(1) | O(V) |
이전에 배운 우선순위 큐를 이용한 다익스트라 최단 경로 알고리즘은 인접 리스트를 이용하여, 노드의 개수만큼 리스트를 만들어서 각 노드와 연결된 모든 간선에 대한 정보를 리스트에 저장하였다.
플로이드 워셜 알고리즘은 인접 행렬을 이용하여 모든 노드에 대하여 다른 노드로 가는 최소 비용을 V^2크기의 2차원 리스트에 저장한 뒤 해당 비용을 갱신하여 최단 거리를 계산하였다.
여기서 중요한 점은,
문제를 접할 때 메모리와 시간을 염두하고 알고리즘을 선택해서 구현해야 한다는 것이다.
최단 경로를 찾는 문제를 접했을 때, 만약 노드의 개수가 적은 경우에는 플로이드 워셜 알고리즘을 이용할 수 있다.
하지만, 노드와 간선의 개수가 모두 많다면, 우선순위 큐를 이용한 다익스트라 알고리즘을 이용하는 것이 유리하다.
(이전에 이러한 부분에 소홀히 했었다)
서로소 집합
공통 원소가 없는 두 집합을 의미한다.

서로소 집합 자료구조
서로소 부분 집합들로 나누어진 원소들의 데이터를 처리하기 위한 자료구조
union과 find이 2개의 연산으로 조작할 수 있다.
union(합집합)은 2개의 원소가 포함된 집합을 하나의 집합으로 합치는 연산이다.
find(찾기) 연산은 특정한 원소가 속한 집압이 어떤 집합인지 알려주는 연산이다.
스택과 큐가 각각 push, pop연산으로 이루어진 것처럼, 서로소 집합 자료구조는 합집합, 찾기 연산으로 구성된다.
서로소 집합 계산 알고리즘 과정
트리 자료구조를 이용하여 서로소 집합을 계산한다.
- union연산을 확인하여, 서로 연결된 두 노드 A, B를 확인
① A와 B의 루트 노드 A', B'를 각각 찾음
② A'를 B'의 부모 노드로 설정 (B'가 A'를 가리키도록) - 모든 union 연산을 처리할 때까지 1번 과정 반복
기본적인 서로소 집합 알고리즘 코드


각 값들을 입력받고, 입력받은 데이터를 토대로, find_parent() 함수에서는 해당 노드의 부모 노드가 본인 노드가 아니라면, 즉 루트 노드가 아니라면, 재귀 함수를 통해 루트노드를 찾고 리턴한다.
union_parent() 함수에서는 각 노드의 부모값들을 find_parent() 함수에서 리턴받고, 해당 값들 중, 더 작은 값(우선순위가 더 높은 값)을 더 큰값의 루트 노드로 설정한다.
다만, 위의 find_parent() 함수는 비효울적이다. 최악의 경우 모든 노드를 다 확인하게 되면 시간 복잡도는 O(V)이다.
union의 연산 순서가 (4, 5), (3, 4), (2, 3), (1, 2) 라고 가정하면 아래와 같은 순서로 나열된다.

여기서 5의 루트를 찾기 위해서는 모든 노드드르이 부모 노드를 거슬러 올라가야 하기 때문에 최대 O(V)의 시간이 소요되고 결과적으로 노드의 개수가 V개, find, union 연산의 개수가 M개라면, 전체 시간 복잡도는 O(VM)이나 된다.
하지만 경로 압축 기법을 적용하면 시간 복잡도를 개선할 수 있다.
find 함수만 변경하면 된다.

이전에 각 부모 노드를 리턴한 것과는 다르게, 해당 노드의 루트 노드가 바로 부모 노드가 된다.
이전의 예시와 같이 union의 연산 순서가 (4, 5), (3, 4), (2, 3), (1, 2) 라고 가정하면 아래와 같은 순서로 나열된다.
결과적으로 경로 압축 기법을 이용하면 루트 노드에 더욱 빠르게 접근할 수 있기 때문에, 기존의 알고리즘보다 시간 복잡도가 개선된다.
서로소 집합을 활용한 사이클 판별
서로소 집합은 다양한 알고리즘에 사용될 수 있다.
특히 서로소 집합은 무방향 그래프 내에서의 사이클을 판별할 때 사용할 수 있다는 특징이 있다.
union 연산은 그래프에서의 간선으로 표현될 수 있다.
따라서 간선을 하나씩 확인하면서 두 노드가 포함되어 있는 집합을 합치는 과정을 반복하면 사이클을 판별할 수 있다.
- 각 간선을 확인하며 두 노드의 루트 노드를 확인
① 루트 노드가 서로 다르다면 두 노드에 대하여 union 연산을 수행
② 루트 노드가 서로 같다면 사이클이 발생한 것 - 그래프에 포함되어 있는 모든 간선에 대하여 1번 과정 반복
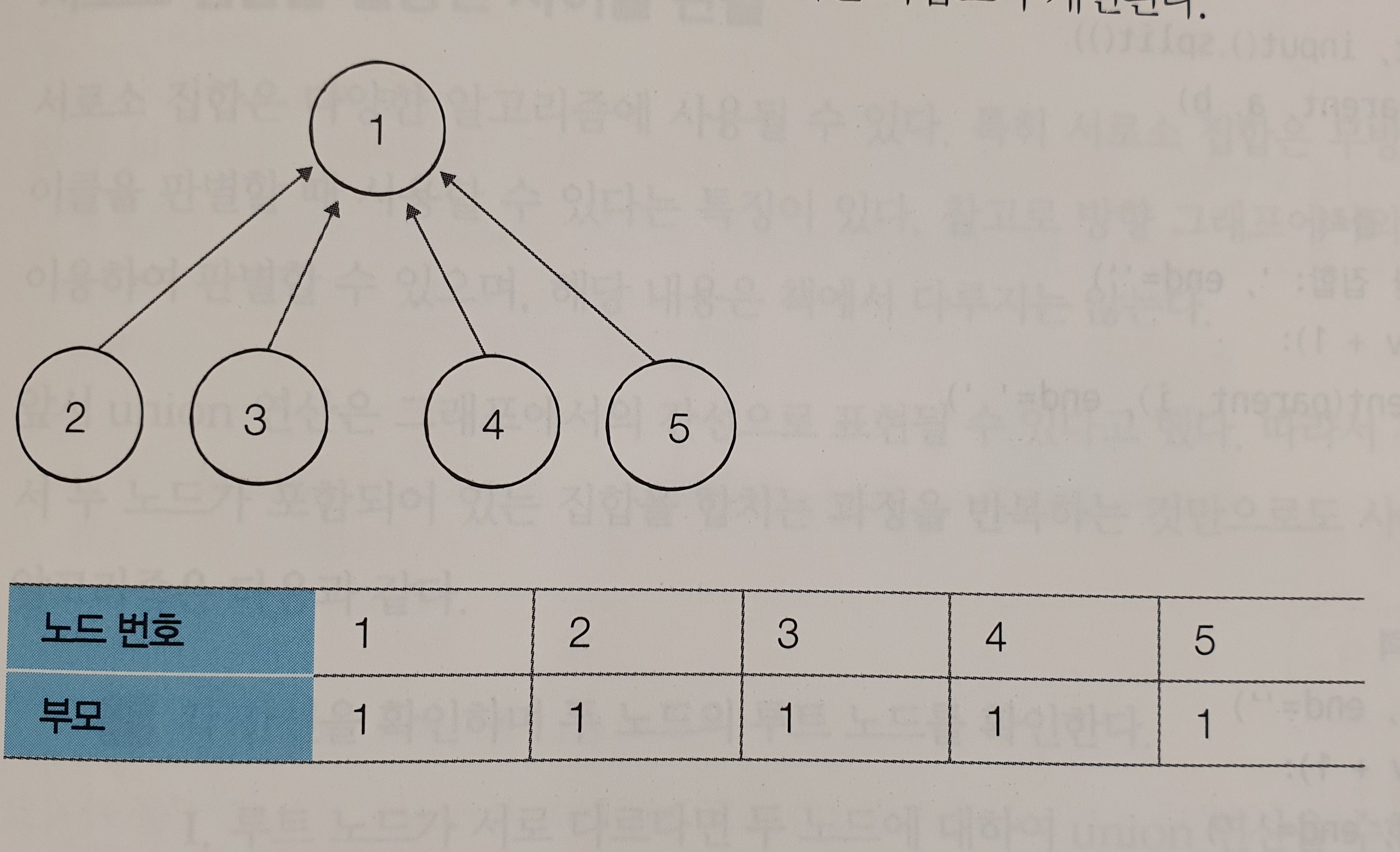
① 초기 단계. 자기자신을 부모로 설정하는 형태로 부모 테이블 초기화

| 인덱스 | 1 | 2 | 3 |
| 루트 | 1 | 2 | 3 |
② (1, 2) 확인. 각각 루트노드가 1, 2이다. 더 큰 번호를 갖는 노드 2의 부모 노드를 1로 변경

| 인덱스 | 1 | 2 | 3 |
| 루트 | 1 | 1 | 3 |
③ (1, 3) 확인. 각 루트 노드가 1, 3이다. 더 큰 번호를 갖는 노드 3의 부모 노드를 1로 변경
| 인덱스 | 1 | 2 | 3 |
| 루트 | 1 | 1 | 1 |
④ (2, 3) 확인. 루트 노드가 1로 동일 -> 사이클 발생

사이클 판별 알고리즘은 그래프에 포함되어 있는 간선의 개수가 E개 일 때 모든 간선을 하나씩 확인하며, 매 간선에 대하여 union 및 find 함수를 호출하는 방식으로 동작한다.
간선에 방향성이 없는 무향 그래프에서만 적용 가능하다.
서로소 집합을 활용한 사이클 판별 코드

union, find 함수는 이전에 경로 압축 기법의 코드와 동일하지만, 데이터를 입력받음과 동시에 해당 노드의 부모노드를 확인하고, 상호간의 부모노드가 동일하다면 사이클이 발생했다고 출력하고 그렇지 않은 경우는 두 노드를 합친다.
위 과정을 간선의 개수만큼 반복한다.
신장 트리
하나의 그래프가 있을 때 모든 노드를 포함하면서 사이클이 존재하지 않는 부분 그래프를 의미한다.
모든 노드가 포함되어 서로 연결되면서 사이클이 존재하지 않는다는 조건은 트리의 성립조건이기도 하다.
그래서 이러한 그래프를 신장 트리라고 부른다.

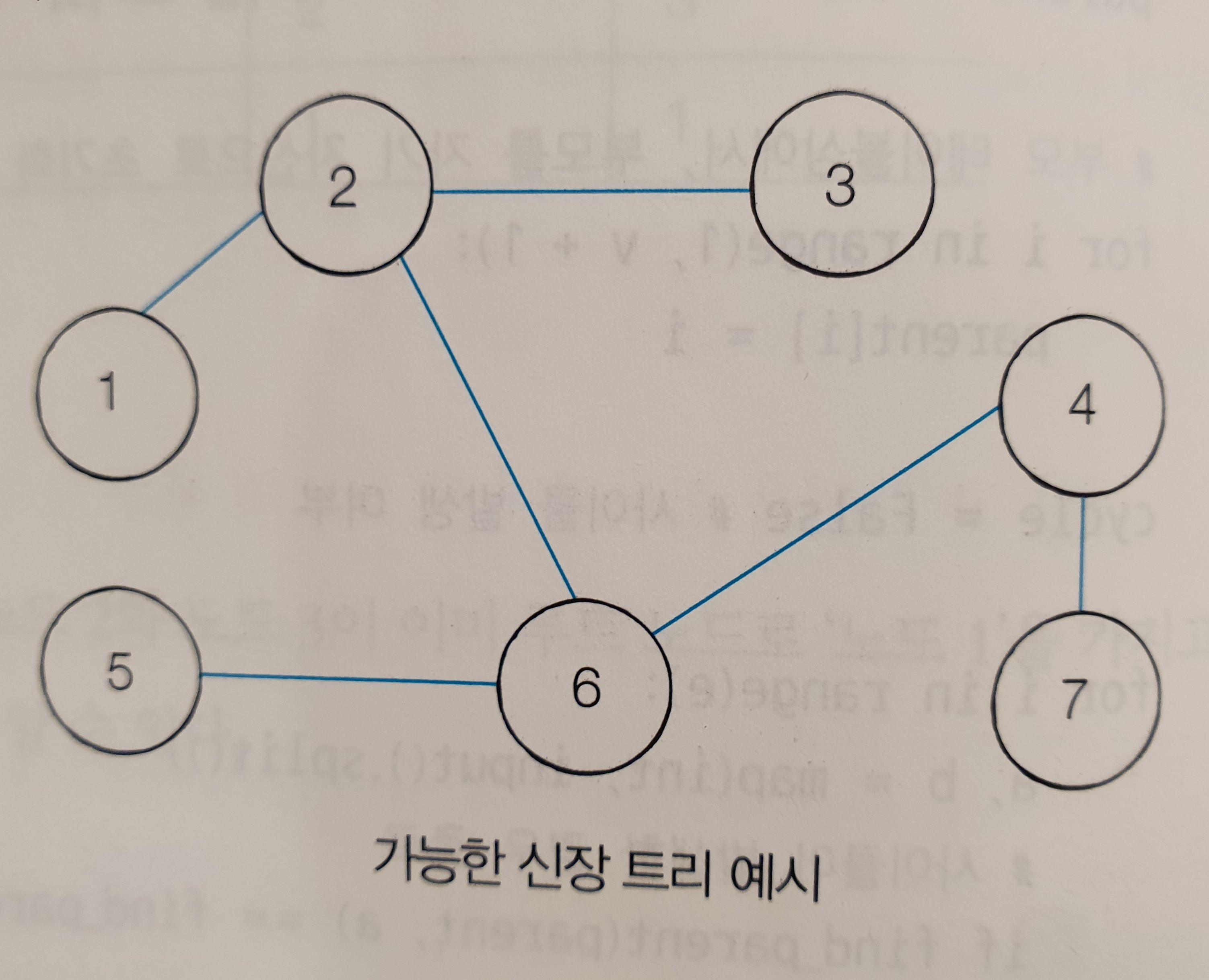
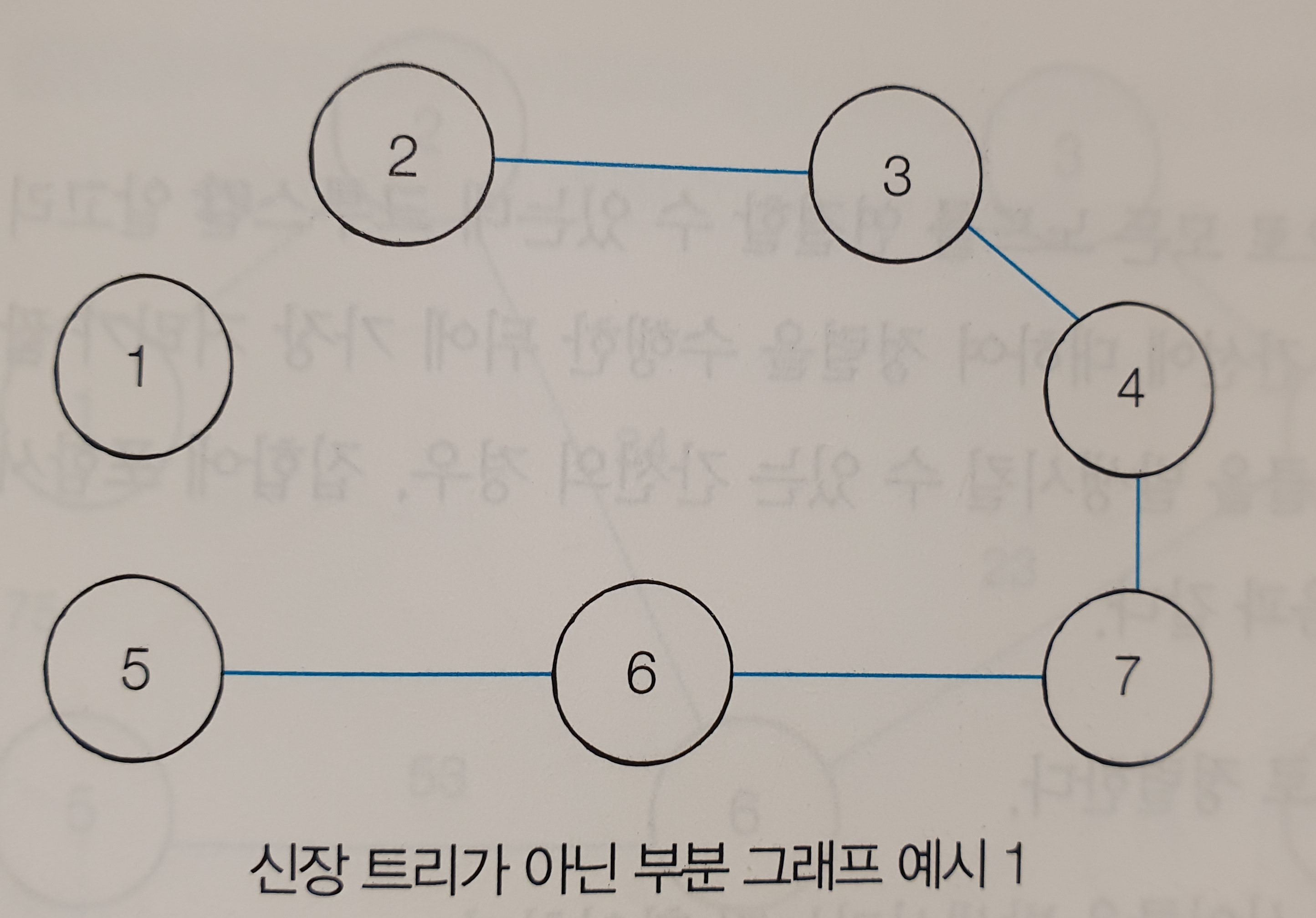
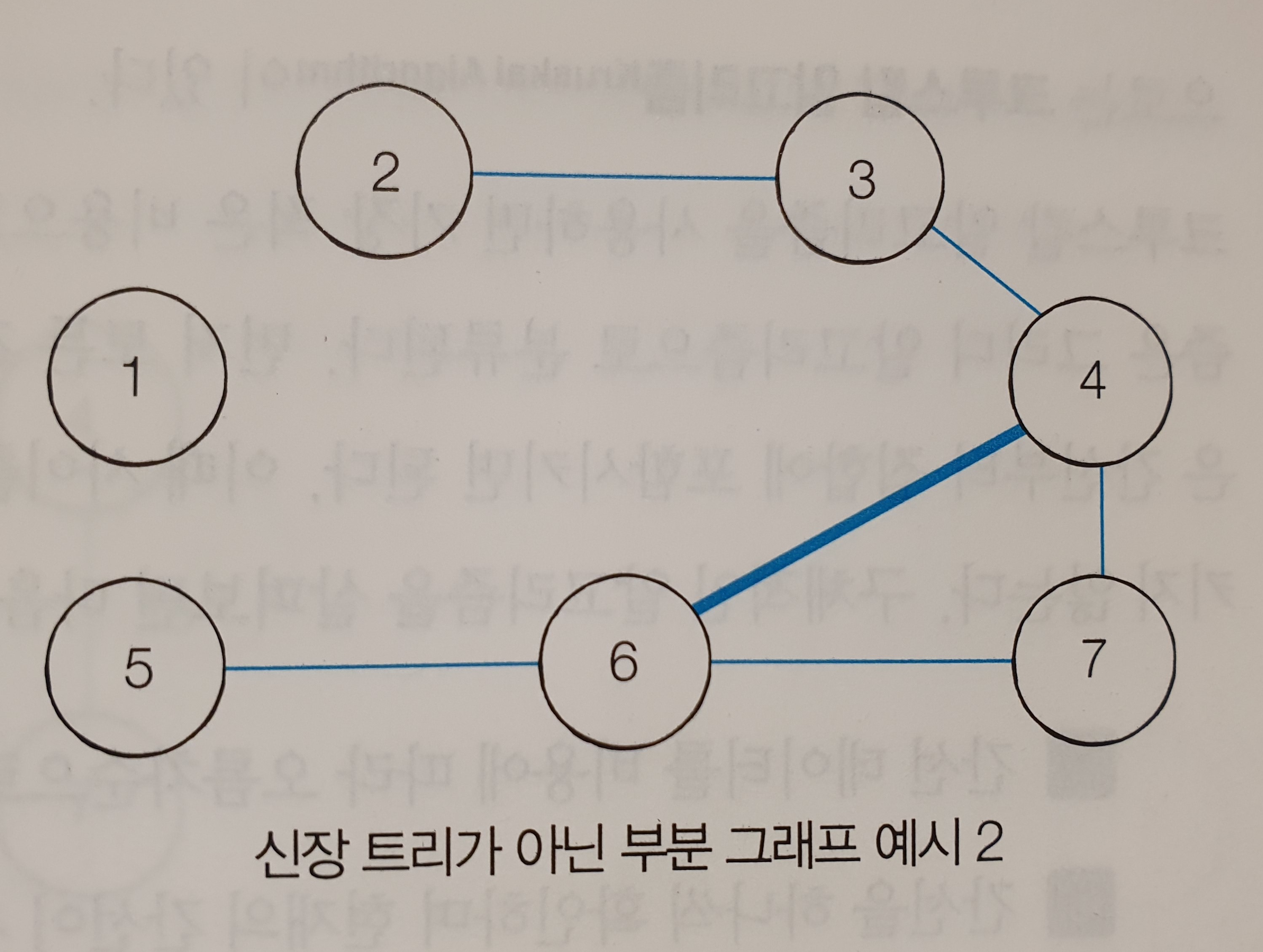
예시1은 노드1을 포함하고 있지 않기 때문에 신장 트리에 해당하지 않고, 예시2는 노드1을 포함하지 않을 뿐만 아니라, 사이클이 존재하기 때문에, 신장 트리에 해당하지 않는다.
크루스칼 알고리즘
우리는 다양한 문제속에서 가능한 한 최소한의 비용으로 신장 트리를 찾아야 할 때가 있다.

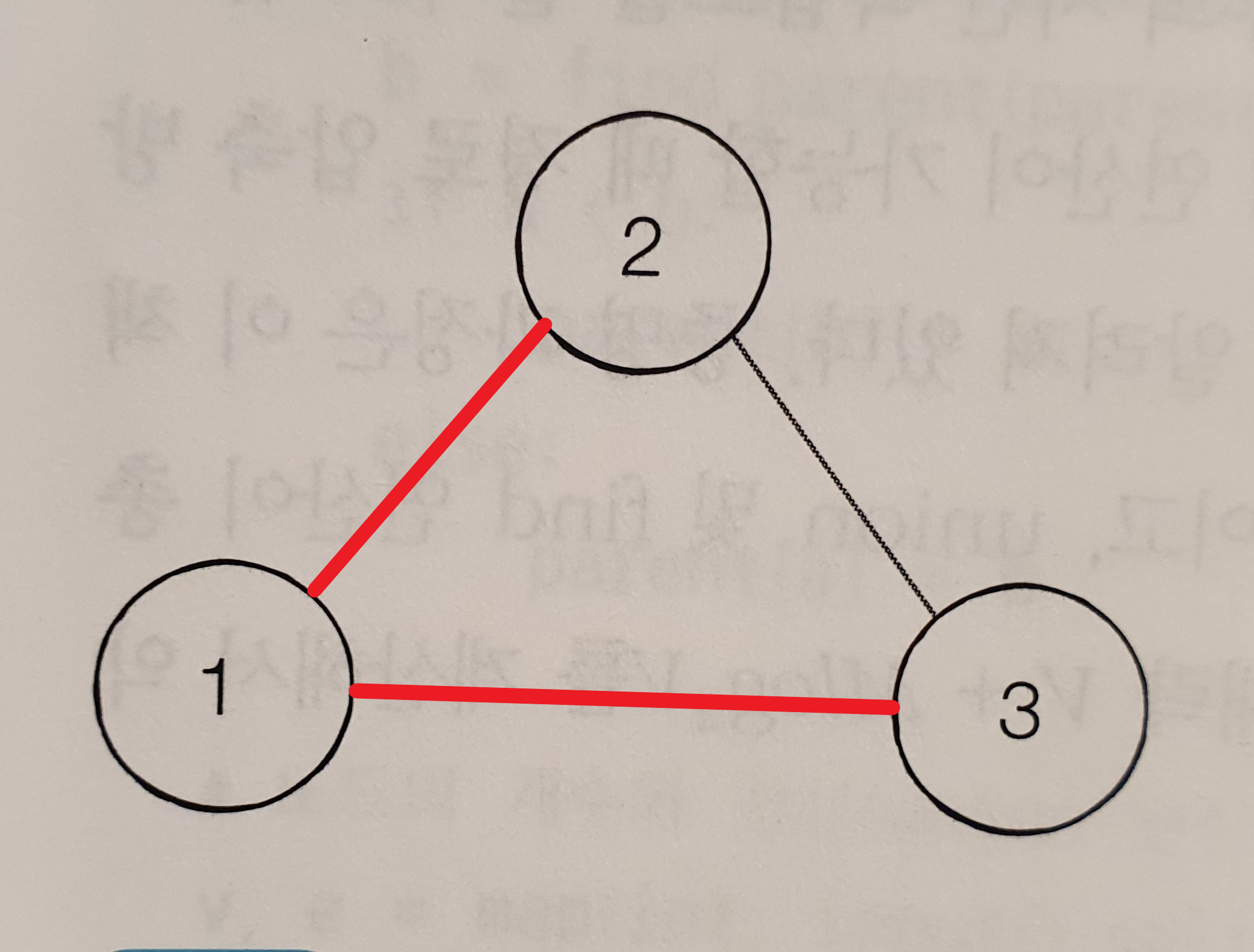
1, 2, 3이라는 도시와 각 도시를 연결하는 도로를 건설하는 비용이 위와 같이 정해져있다고 가정해보면, 모든 도시가 연결하는데에 최소 비용으로 하고자 한다면, 모든 경우의 수를 고려해보아야 한다.
① 23 + 13 = 36
② 23 + 25 = 48
③ 25 + 13 = 38
①의 경우가 최소 비용이다. 아래의 그림과 같다.

이처럼 신장 트리 중에서 최소 비용으로 만들 수 있는 신장 트리를 찾는 알고리즘은 '최소 신장 트리 알고리즘' 이라고 한다.
대표적인 최소 신장 트리 알고리즘으로는 크루스칼 알고리즘이 있다.
크루스칼 알고리즘은 가장 적은 비용으로 모든 노드를 연결한다는 점에서 그리디 알고리즘으로 분류된다.
먼저 모든 간선에 대하여 정렬을 수행한 뒤에 가장 거리가 짧은 간선부터 집합에 포함시키면 된다.
이때 사이클을 발생시킬 수 있는 간선의 경우, 집합에 포함시키지 않는다.
- 간선 데이터를 비용에 따라 오름차순으로 정렬
- 간선을 하나씩 확인하며 현재의 간선이 사이클을 발생시키는지 확인
① 사이클이 발생하지 않을 경우 최소 신장 트리에 포함
② 사이클이 발생하는 경우 최소 신장 트리에 포함시키지 않음 - 모든 간선에 대하여 2번 과정을 반복
크루스칼 알고리즘 코드


기존의 find함수와 union함수는 동일하고, 입력받은 데이터값들 중에서 노드, 노드, 간선 비용 순으로 입력 받았지만, 간선 데이터를 저장하는 리스트에는 비용을 (비용,노드, 노드)의 튜플 형태로 삽입하였다.
오름차순으로 정렬하고자 할 때, 가장 앞에 있는 데이터값을 기준으로 정렬되기 때문이다.
그리고 반복문으로 간선 리스트의 데이터값들을 가져와서 각각의 부모 노드를 비교하여 부모 노드가 서로 같다면, 사이클을 발생시킬 수 있기 때문에 제외하고, 그렇지 않은 경우에만 두 노드를 합치고(union), 두 노드간의 간선 비용을 누적하여, 모든 간선을 확인한 후, 누적된 비용을 출력한다.
위상 정렬
순서가 정해져 있는 일련의 작업을 차례대로 수행해야 할 때 사용할 수 있는 알고리즘이다.
방향 그래프의 모든 노드를 '방향성에 거스르지 않도록 순서대로 나열한 것' 이다.
예시로는 우리가 흔히 접할 수 있는 '선수과목을 고려한 학습 순서 설정'이다.
우리학교 기준으로 설명하면, 자료구조를 듣기 위해서는 객체2를 선수강으로 들어야하고, 객체2를 듣기 위해서는 객체1을 선수강으로 들어야 한다.
이때 각 '자료구조', '객체2', 객체1'을 각각 노드로 표현하고, 각 노드에 따라 방향성을 갖는 간선을 그릴 수 있다.
즉 그래프상에서 선후 관계가 있다면, 위상 정렬을 수행하여 모든 선후 관계를 지키는 전체 순서를 계산할 수 있다.
진입차수란? 특정한 노드로 들어오는 간선의 개수를 의미한다.
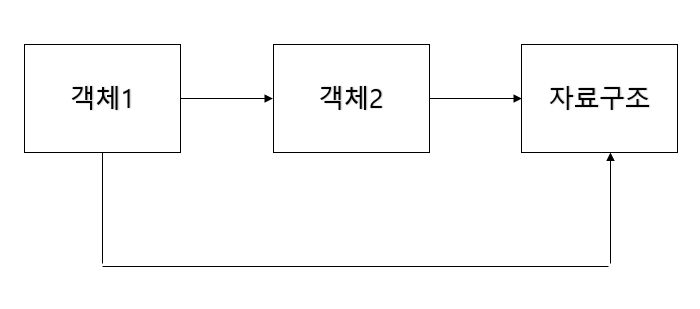
위의 '자료구조' 노드는 2개의 선수과목을 갖고 있다.
즉, 그래프상에서 진입차수가 2인 것을 확인할 수 있다.
위상 정렬 알고리즘
- 진입 차수가 0인 노드를 큐에 넣음
- 큐가 빌 때까지 다음의 과정을 반복
① 큐에서 원소를 꺼내 해당 노드에서 출발하는 간선을 그래프에서 제거
② 새롭게 진입차수가 0이 된 노드를 큐에 넣음
큐가 빌 때까지 큐에서 원소를 계속 꺼내서 처리하는 과정을 반복한다.
만약 모든 원소가 방문하기 전에 큐가 빈다면 사이클이 존재한다고 판단할 수 있다.
사이클이 존재하는 경우 사이클에 포함되어 있는 원소 중에서 어떠한 원소도 큐에 들어가지 못하기 때문이다.
위상 정렬 코드


입력된 데이터 값을 토대로 graph라는 list를 만들고, 도착 노드에 진입 차수의 값을 증가시킨다.
topology_sort() 함수에서 진입차수가 0인 노드를 쿠에 삽입하고 q가 빌 때까지 반복하는데, 매번 q에서 꺼낸 노드를 result라는 list에 삽입하고, 해당 노드와 연결된 노드들의 진입 차수값을 1씩 감소시키고, 진입 차수가 0이된 노드를 q에 삽입한다.
위의 과정을 q가 빌 때까지 반복한 후, 반복문을 빠져나와서 result list를 출력한다.
위상 정렬의 시간 복잡도
위상 정렬의 시간 복잡도는 O(V+E)이다. 위상 정렬을 수행할 때는 차례대로 모든 노드를 확인하고, 해당 노드에서 출발하는 간선을 차례대로 제거한다. 결과적으로 노드와 간선을 모두 확인하기 때문에, O(V+E)의 시간을 소요한다.
팀 결성
문제 : 교재 298p 참고
나의 코드

앞서 배운 개념들을 그대로 사용하면 쉽게 풀 수 있는 문제였다.
find함수와 union함수도 수정할 필요없이 바로 사용하였고, 단지 각 줄의 첫 번째 입력값에 따라서 다른 역할을 하도록 제어문만 구현하면 쉽게 풀 수 있다.
해설의 코드와도 거의 유사해서 해설 코드는 생략하겠다.
해설코드와 다른점이 있긴 했는데, 본인은 YES or NO의 값을 순서대로 리스트에 담아 한꺼번에 출력했지만, 해설코드를 참고하고 실행해보니, 필자의 의도는 1을 시작으로 입력할 때마다 바로바로 YES or NO라는 출력값이 나오는 것이었던거 같다.
도시 분할 계획
문제 : 교재 300p 참고
나의 코드(오답)


크루스칼 알고리즘을 통해 최소 신장 트리를 만들어서 모든 마을이 사이클이 존재하지 않고 이어진 모습까지는 구현을 했다. 하지만 2개의 마을로 분할하라는 문제에서 막히게 되었다.
해설을 참고한 코드


정말 간단하게 해결할 수 있는 문제였다. 최소 신장 트리를 만드는 것까지는 좋았다...
이 트리를 실제로 그려보기라도 했으면, 아이디어가 떠올랐을텐데, 좀 많이 아쉽다.
문제에서는 최소 비용을 요구했으니, 구현해낸 최소 신장 트리에서 가장 비용이 큰 간선 하나를 제거한다고 가정하고, 모든 비용에서 가장 비용이 큰 값을 빼주기만 하면되는 것이었다.
어차피 코드내에서 간선의 비용에 대하여 오름차순으로 정렬하였기 때문에, edges 리스트의 마지막 값을 구하고 그 값을 전체 비용에서 빼주면 간단하게 해결할 수 있는 문제였다. 어려운 문제가 아니었는데,,,,,,
커리큘럼
문제 : 교재 303p 참고
문제를 못풀었다;;;
이전에 다룬 위상 정렬 알고리즘을 사용해서 접근하면 되겠다는 생각까지하고, 구상까지는 하였다.
근데 입력 예시를 보고 좀 멘붕이 왔던 것 같다.

입력값의 개수가 유동적이다보니 입력값들을 컨트롤하는데에 있어서 많이 고민하다가 결국 풀지 못했다.
알고리즘의 개념문제라기 보다는 기본적인 파이썬 문법에서의 부족함이 드러난 것 같다.
해설을 참고한 코드


17번째 코드가 본인이 해결하지 못한 입력 관련 코드이다.
좀 당황했다.. 보고도 이해가 바로 안갔기 때문이다. 슬라이싱 개념인데, 솔직히 그냥 대충 보고 넘겼던거 같다.
바로 구글링해서 찾아보고, 직접 예시로 코드 몇개로 돌려보고 이해가 됐다.
0번째 값은 어차피 시간값이라 해당 사항이 없고, 그 이후의 값들이 진입차수의 값과 graph list를 수정하기 위해 필요한 값들이다.
하지만 2번째줄 입력값처럼 첫 번째 강의(노드)는 진입차수가 존재하지 않기 때문에 걸리는 시간값만 데이터로 받는 경우가 존재하고 5번째 줄 입력값처럼 복수로 여러개 진입되는 강의가 존재하는 경우가 존재하기 때문에, 입력값의 개수가 가변적이다.
이를 [1:-1]이라는 슬라이싱을 통해서 1번째 값부터 마지막의 이전 데이터값들만 반복문에서 다루도록 구현하였다.
위의 문제는 이전에 순서만 다뤘던 위상 정렬 알고리즘에서 추가적으로 시간값을 더하는 연산이 추가되었고, 입력받은 time값을 저장한 time 리스트와 별개로 최종적으로 각 강의를 수강하기까지의 최소 시간을 저장할 result 리스트를 만드는 과정에서 copy 라이브러리의 deepcopy() 함수를 사용하였다.
리스트의 경우, 단순히 대입 연산을 하면 값이 변경될 때 문제가 발생할 수 있기 때문에, 리스트의 값을 복제해야 할 때는 deepcopy() 함수를 사용해야 한다.
느낀점
마지막 문제에서 느끼는게 많았다.
문제에 대한 아이디어가 떠오르더라도 기본적인 문법이 확실하게 잡혀있지 않더라면, 의미가 없다.
평소에 다루지 않던 문법이 갑자기 필요로 하게 되니, 문제에 접근도 하지 못하게 되었다.
슬라이싱 개념은 기존에 본적은 있지만 심도있게 다룬적이 없었고, copy 라이브러리와 deepcopy의 개념은 아직 접해보지 못했다.
이번 part까지 코딩 테스트에서 다루는 기본적인 알고리즘들의 개념들을 살펴보게 되었다.
개념도 다루고 실전문제들을 풀어보면서 느끼는게 많았다.
원래 계획은 지금까지 다룬 내용들을 빠르게 복습하고, 책 후반부에 있는 기출문제를 풀어보고자 하였는데, 파이썬의 기본 문법에서 부족함이 보였기 때문에, 기출문제를 조금 미루더라도 문법 부분을 확실히 잡고 넘어가야 할 필요성을 느꼈다.
'이것이 취업을 위한 코딩테스트다 with 파이썬' 카테고리의 다른 글
| 코딩 테스트를 위한 파이썬 기본 문법 (0) | 2021.01.08 |
|---|---|
| 최단 경로 (0) | 2021.01.07 |
| 다이나믹 프로그래밍 (0) | 2021.01.03 |
| 이진 탐색 (0) | 2021.01.02 |
| 정렬 (0) | 2021.01.01 |



